How to Optimize Your Database like a Pro: Tips You Would Not Learn in Tutorials
You have built a flawless front end, your APIs respond in milliseconds, and your servers are more than capable—yet your app still feels sluggish. Why? The culprit is often an unoptimized database.
Retrieving data from a database is easier when executed correctly, and no, we're not talking about your Excel sheet. It boils down to poorly designed schemas and inefficient SQL queries that can dramatically increase response times, consume excessive memory or disk I/O, and create major bottlenecks when scaling.
Most tutorials stop at writing basic SELECT queries. However, in real-world systems, performance hinges on far more thoughtful database design, efficient query writing, sub-query caching, identifying slow queries, and smart indexing, as well as ongoing performance monitoring.
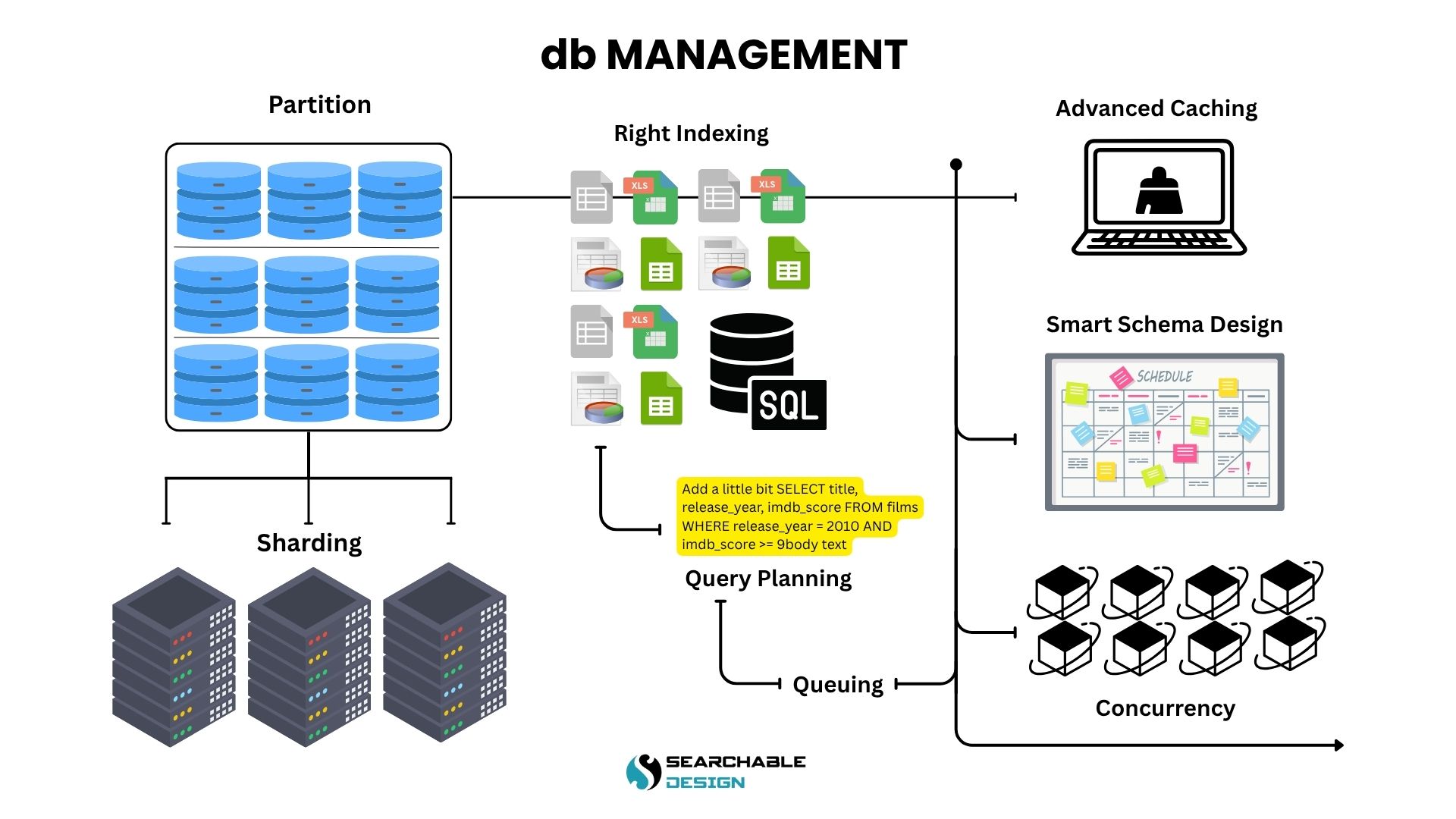
Let us guide you through the steps that seasoned developers typically take, often overlooked in tutorials, from crafting scalable schemas to optimizing queries and managing massive datasets with ease.
Where to Start with Optimizing the Database
Slow databases often start when designing a database, sometimes more often than you may imagine.
Poor database design can drastically affect performance. Here’s a brief overview of common mistakes and how to fix them:
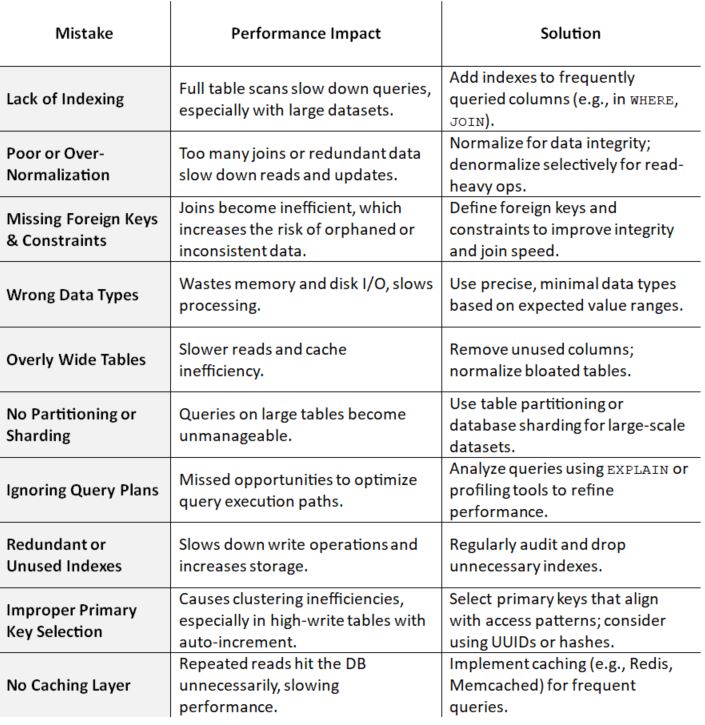
A well-designed database reduces query time, improves scalability, and keeps your app responsive, even as data grows.
Now, let us talk about them in detail.
1. Start with Optimizing the Infrastructure and I/O
Many developers overlook the basics of where their database resides. Factors such as disk speed, CPU, and memory make a significant difference—if your storage is slow or your server has low memory, your database will struggle, even if your queries are perfect.
For example, PostgreSQL generates a large number of logs in the background (called WALs). If disk memory is full, every insert or update may take longer to complete.
Similarly, if the memory is full, the database will limit cache storage, forcing the system to retrieve data from the disk’s main memory, which creates more logs in the process, ultimately making execution slower.
Here are some key metrics to consider.

Quick Checklist
- Utilize SSDs (solid-state drives) for improved read and write speeds.
- Make sure you are not running too many services on the same machine.
- Add read replicas if you need to spread out the API load.
- Reduce the number of read/write operations by optimizing data structures and algorithms to improve performance.
- Group multiple I/O requests into larger, single operations.
- Minimize the distance between servers and clients by utilizing efficient network protocols or cloud networking solutions.
Many enterprises initially opt for cheaper infrastructure to offset expenses, but it often ends up costing more. Better to invest in design infrastructure that can easily scale to handle increasing workloads and implement security protocols to protect infrastructure and data.
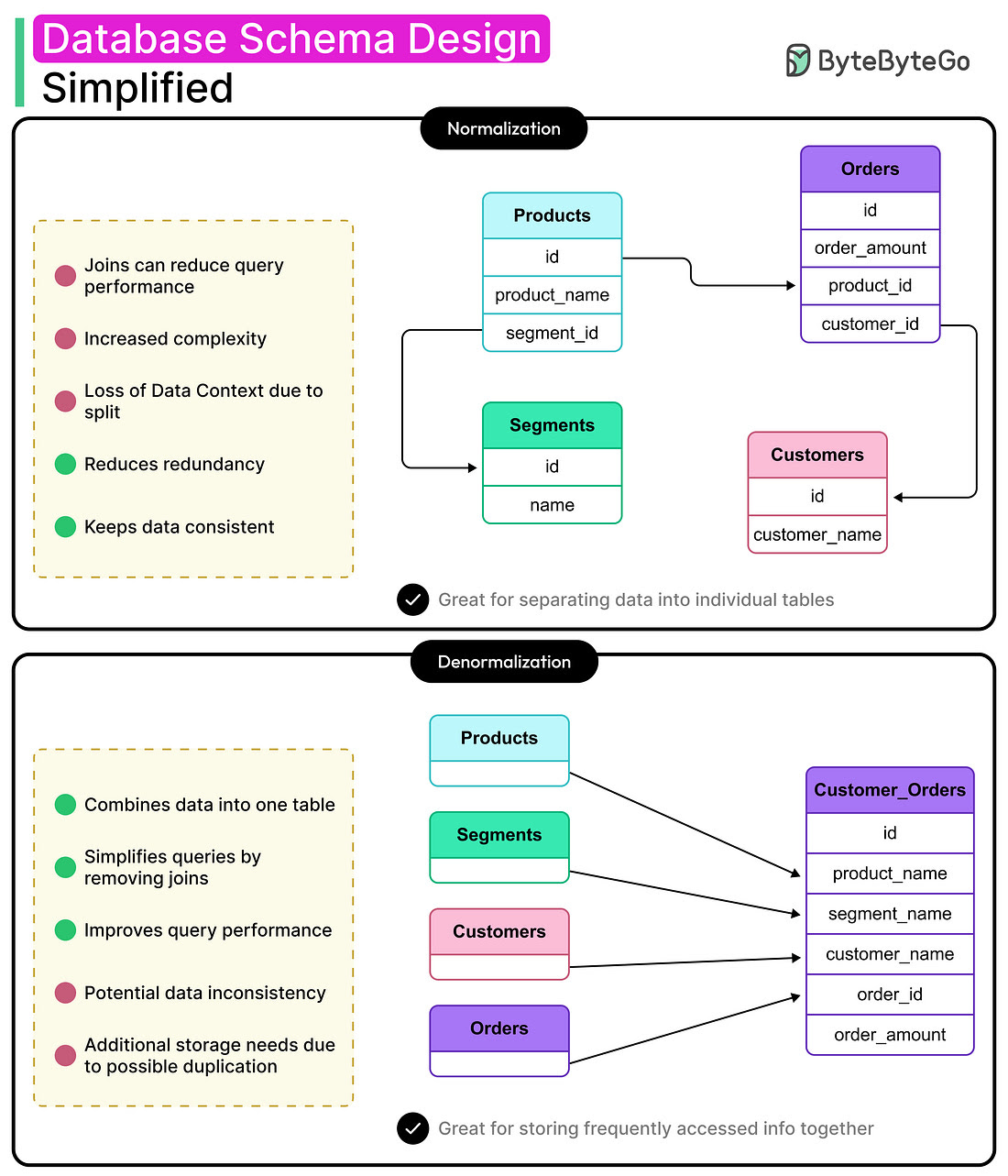
2. Smart Schema Design and Normalization
Database schemas decide how your data is organized. In tutorials, you learn to normalize tables and break them down to reduce duplication. That is great for data integrity, but in real-world applications, excessive normalization can slow down queries, especially when they involve numerous joins.
In the professional world, there should be a balance between normalization (clean data, fewer errors) and denormalization (faster queries with fewer joins).
Normalized tables are helpful for everyday transactions, and denormalized views or copies are for dashboards and reports.
Here is how to decide using the Schema decision matrix.
Quick Checklist
- Normalize for data consistency. For example, User profiles and data catalog.
- Denormalize for speed when you expect a lot of reads. For example, Blog posts and E-Commerce orders.
- Use summary tables for reports instead of real-time joins. For example, a monthly sales summary and user activity statistics.
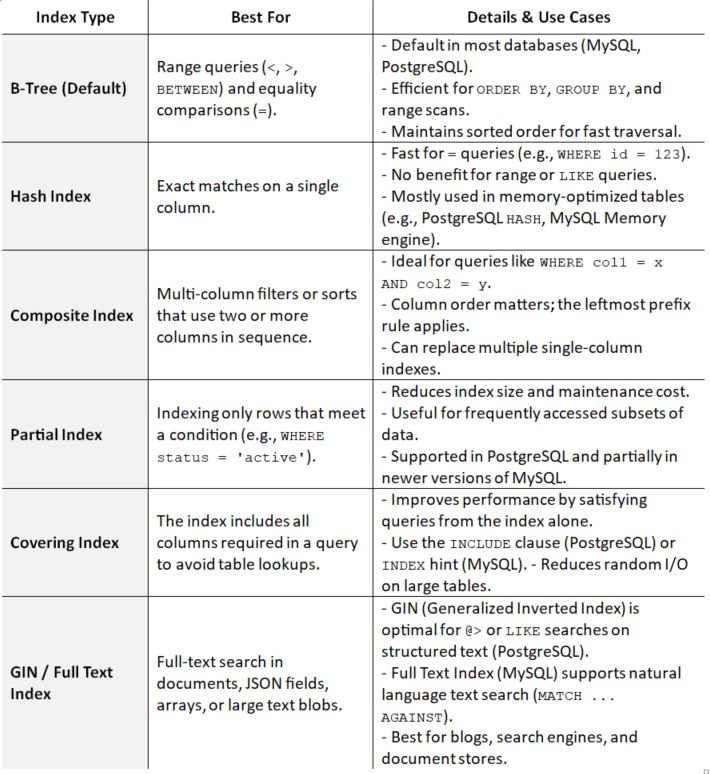
3. Right Indexing
Indexes help your database find data more efficiently, much like a table of contents in a book.
However, every index adds overhead when you insert or update data, and adding too many indexes slows things down, especially during ‘write’ execution.
Therefore, it is essential to create indexes that align with your query patterns. If you often filter by user_id and created_at, a combined index on both will help more than separate indexes.
Which type of index should I choose?
Top Mistakes to Avoid
- Over-indexing: Having too many indexes slows down write-heavy workloads and increases storage usage.
- Indexing Low-Cardinality Columns: Columns with few unique values (e.g., gender, status) typically do not benefit significantly from indexing, often resulting in inefficient index scans with minimal performance gain.
- Duplicating indexes: Drop unused, duplicate, or overlapping indexes regularly to speed up writes and save space.
- Blindly Following ORM Defaults: ORMs like Sequelize, Hibernate, or Django may auto-generate unnecessary indexes. Review schema changes and manually optimize as needed.
- Not Using Partial or Conditional Indexing When Needed: Indexing all rows when only a subset is frequently queried increases index size without benefit. Use partial indexes for targeted performance.
- Not Testing Index Impact on Writes: Indexes can drastically affect write latency. Always benchmark with realistic workloads before adding new components.
- Forgetting to Monitor Index Usage: Some indexes remain unused over time but still consume space and negatively impact performance. Use tools like PostgreSQL’s pg_stat_user_indexes or MySQL’s SHOW INDEX.
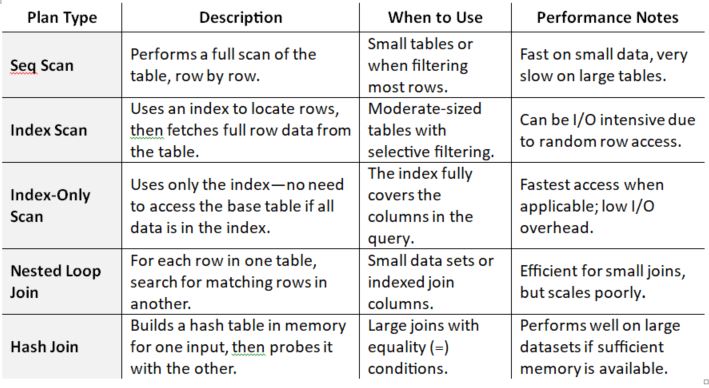
4. Query Planning
Even if your SQL query appears to be fine, it may still be slow, primarily because the database is performing a full-table scan or using an incorrect join method (joining two or more columns).
It is always best to check your query plan using tools like EXPLAIN or EXPLAIN ANALYZE to see how the database actually executes the query.
Here are some common SQL Query Planning strategies.
Things to Remember
- Indexes speed up reads, but too many can slow down writes and consume storage.
- Queries that can be served directly from indexes avoid costly table lookups.
- Filter Early, Join Later: Reduce the dataset before joining—smaller sets = faster joins.
- Watch for Sequential Scans: Acceptable for small tables; avoid for large ones unless scanning most rows is necessary.
- Optimize JOINs Based on Size: Use Nested Loop for small joins, Hash Join or Merge Join for large datasets.
- Use EXPLAIN or EXPLAIN ANALYZE: Always review the actual query plan to detect bottlenecks.
- **Avoid SELECT *** Fetching all columns increases I/O and often prevents index-only scans.
- Add LIMIT/OFFSET for Pagination to prevent loading too much data into memory during reads.
- Up-to-date stats help the planner choose the optimal path.
- Minimize Subqueries and Views: Flatten complex nested queries where possible for clarity and performance.
- Partition Large Tables: Use table partitioning to isolate scans to relevant subsets.
- Leverage Materialized Views: Precompute expensive aggregations or joins for faster access.
5. Optimize Bulk Operations and Queueing
Inserting or updating one row at a time is a slow process. Real systems, such as transactional systems, often suffer due to poorly optimized writes.
Instead of inserting 1,000 rows one at a time, insert them all at once. It reduces locking, I/O, and CPU usage.
If you are handling real-time data, use a queue system (like Kafka or RabbitMQ) and write in batches. This way, your app stays fast even when handling high traffic.
How to Improve 'Write' Performance
- Minimize Indexes on Write-Heavy Tables: Each index adds overhead during INSERT, UPDATE, and DELETE operations. Use only essential indexes; remove redundant or unused ones.
- Batch Inserts Instead of Single Rows: Insert multiple rows in a single query, rather than one at a time, to significantly reduce transaction and network overhead.
- Disable Constraints Temporarily (When Safe): When performing bulk inserts, temporarily disable foreign keys or unique constraints, then re-enable and validate them only after the operation is complete.
- Use Transactions Efficiently: Group multiple writes into a single transaction to reduce commit overhead. Avoid opening transactions longer than necessary.
- Optimize Data Types: Using smaller, more appropriate data types reduces disk I/O and memory usage. E.g., use INT instead of BIGINT where possible.
- Clean Up Unused Triggers & Cascades: Triggers can silently add overhead. Disable them if not needed during writes and avoid cascading deletes or updates unless essential.
- Use In-Memory Tables or Queues for High-Speed Buffering: Temporarily store incoming data in memory (e.g., Redis, MEMORY tables) and flush in batches.
- Reduce Lock Contention: Minimize long transactions or frequent writes to the same rows, and consider optimistic locking for high-concurrency environments.
6. Advanced Caching Techniques
Caching or memory cache significantly reduces database load by storing data in memory, allowing it to be retrieved quickly than from disk. Hence, modern browsers, applications, and cloud-based software utilize caching to reduce operation time.
Here are a few examples of cache management.
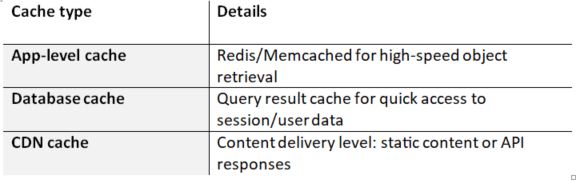
However, practicing caching alone may not be sufficient to solve the problem, especially when a product involves dynamic data. Enterprises should adopt smart caching techniques to optimize database performance for all types of data.
Good Practices for Smart Caching
- Cache Frequently Accessed Data: Identify hot data (e.g., user profiles, product listings) and cache it using tools like Redis or Memcached, thereby reducing the need for repeated database reads for the same queries.
- Use Expiry (TTL) Intelligently: Set appropriate expiration times (timestamps) based on how frequently the data changes -short TTLs for dynamic data and longer TTLs for static or rarely updated data.
- Cache Invalidation on Update: With every server or system update, automatically clear or refresh the cache when the underlying data changes (using a write-through or write-behind strategy), ensuring accuracy and preventing stale data.
- Cache Query Results, Not Raw Tables: Cache specific SQL query results (especially aggregations or complex joins) instead of full tables.
- Use Application-Level Caching: Store results in memory at the app layer for fast access during request handling. For example, use a local in-memory cache (e.g., LRU cache) for user sessions or configurations.
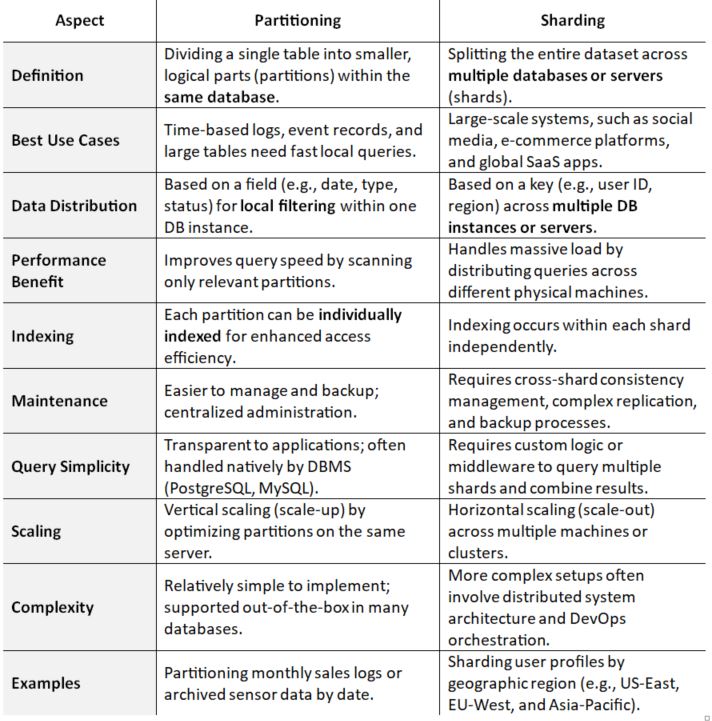
7. Partitioning and Sharding
For tables with hundreds of millions of rows, even the most well-optimized indexes may not be enough to maintain high performance.
That’s where partitioning comes in—it divides a large table into smaller, more manageable segments (partitions), allowing the database engine to search only the relevant subset rather than scanning the entire dataset.
Taking this a step further, sharding distributes these partitions across multiple servers or databases, enabling horizontal scalability. This is especially valuable for high-traffic, data-intensive platforms, such as social networks or large e-commerce systems.
Imagine trying to retrieve and summarize specific records from a dataset of 300,000 rows. Instead of scanning the entire table, you can break it into logical chunks—for example, 10,000-row partitions based on traits like date, user region, or action type. When a query runs, the system accesses only the relevant partition, drastically reducing I/O and improving speed.
To further enhance performance, these partitions can be distributed across multiple servers, relieving pressure on a single database node and enabling better concurrency during peak traffic.
When to Use Partitioning and Sharding
8. Concurrency, Locking, and Isolation Levels
Some applications may have hundreds or even thousands of concurrent users accessing the app simultaneously, often reading or writing the same data.
Without proper concurrency planning and infrastructure in place, users often end up in deadlocks, experience long waits, encounter errors, and eventually uninstall the app.
Here, implementing database isolation can help identify and prevent problems before they escalate.
Database isolation is a critical component of transaction management in relational databases. It ensures that concurrent transactions do not interfere with each other; for instance, transactions are queued, locked, or versioned to ensure the balance is always correct.
Here are the levels of isolation (from lowest to highest)
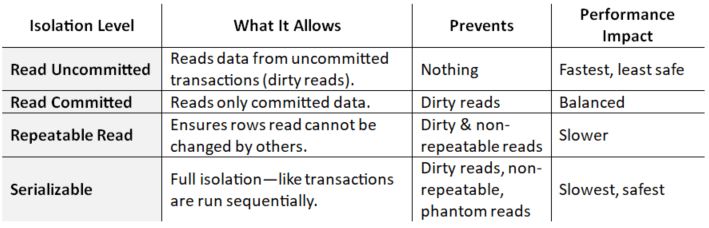
Some Common Concurrency Techniques
Here are some key concurrency control techniques you can adopt to ensure safe, efficient, and consistent database operations when multiple transactions occur simultaneously:
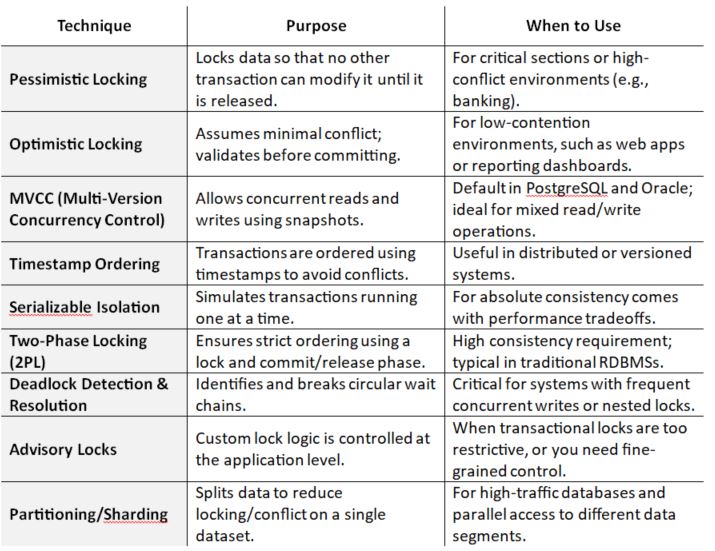
Conclusion
Optimizing a database is more about making informed decisions and applying tricks out of sleeves, and may take more than a one-time tweak. Start with a lifecycle discipline that includes monitoring, design trade-offs, infrastructure understanding, and adaptability if you wish to optimize and scale the database.
By mastering these advanced optimization techniques, you will be able to maintain balance with the needs of real-world systems, beyond tutorials.
Contact Searchable Design, the premier technology solution provider in the US, for high-performance database solutions with real-time monitoring that drive SMBs’ real results.
Related Post


RECOMMENDED POSTS


RECOMMENDED TOPICS
TAGS
- artificial intelligence
- agentic ai
- ai
- deepseek
- machine learning
- llm
- data science
- saas
- ai/ml
- growth engineering
- chatgpt
- gpt
- openai
- ai development
- cloud management
- cloud storage
- customer expectation
- cloud optimization
- aws
- sales growth
- gcp
- social media
- social media marketing
- social influencers
- api
- application
- cybersecurity
- software engineering
- scalable architecture
- mobile development
- modular saas
- api based architecture
- deep learning
- python
- user experience
- app development
- user interface
- data analysis
- data pipeline
- generative ai
- deepfake
- healthcare
- climate change
- llm models
- leadership
- it development
- empathy
- static data
- dynamic data
- ai model
- open source
- xai
- qwenlm
- bpa
- automation
- database optimize
- modern medicine
- growth hacks
- data roles
- data analyst
- data scientist
- data engineer
- data visualization
- productivity
- database management
- sql query
- data isolation
- db expert
- artificial intelligene
- test
ABOUT
Stay ahead in the world of technology with Iowa4Tech.com! Explore the latest trends in AI, software development, cybersecurity, and emerging tech, along with expert insights and industry updates.
Comments(0)
Leave a Reply
Your email address will not be published. Required fields are marked *